
- Annotation, mLearning, and Geocaching Part #1: Scenarios and Technical Requirements
- Annotation, mLearning, and Geocaching Part #2: The Use Case
- Annotation, mLearning, and Geocaching Part #3: Annotating Maps
Text annotation on the web is nothing new. In fact, annotation was a part of Tim Berners Lee’s original conception of the web, described in his 1989 paper ‘Information management: a proposal’ as the ability to ‘add one’s own private links to and from public information,’ but until recently suitable tools were not evident. Today, thanks to a resurgence of interest in annotation on the web, there are mainstream commercial services (Genius.com), open source applications (Hypothesis), and a W3C standards track (Open Annotation Model). Of course, even without dedicated tools and standards many of us have already made a common practice of discussing online content using social networking sites like Facebook or Twitter.
The annotation tools provided by Genius.com have perhaps done the most to bring text annotation into the mainstream. Genius (formerly Rap Genius) relaunched in 2014 and expanded the site’s scope from rap music to the entire web. Since that time the site has been used to annotate State of the Union addresses, Lin-Manuel Miranda’s Hamilton (with Miranda himself creating the annotations), and William Shakespeare’s Hamlet (including notes by Samuel Johnson; Johnson, here, is a ‘Verified Artist’). And perhaps there is no better sign of mainstream success than criticism: several recent articles discuss the practice of web annotation using the Genius platform from the perspective of internet security and abuse.
But are any of these services adequate for our purposes? Annotation software enables the user to select a portion of a resource on the web and then to add an annotation to this selection. It is also common to make these annotations viewable to a larger group enabling a discourse on a particular text. Our use case is not much different than this, only we wish to annotate with different mediums (text, images, video; potentially captured in the field), and we wish to annotate across mediums (maps and text).
Annotating with different mediums
Across many of the available annotation tools the user experience is the same. The Annotator.js demo, the Hypothesis – Web & PDF Annotation Chrome Extension, or even the image annotation tool, Annotorious, all demonstrate a common design practice and use case. Text is highlighted, or a section of an image is selected, and a popup appears allowing the user to enter a text-based annotation.

If we were to express this mode using the Open Annotation Model, the Annotation is comprised of a single Target (the selection of a resource being annotated) and a single Body (the annotation itself), and the latter is a chunk of text.

But despite this practice and expectation, the data model allows users to create annotations of any imaginable form and media type. The Body of an annotation is an equal partner to its Target. Adhering to Linked Data principes (https://en.wikipedia.org/wiki/Linked_data#Principles) it has its own URI and set of properties. This enables us to move beyond the common use case (text annotating text) to annotation bodies that are comprised of videos, images, and really any media type that can be described and accessed on the Web. This satisfies our first requirement, annotation with different mediums.
Close observers of the example above will note that Hypothesis annotation tool does let users insert links to web resources, images, and videos within their text annotation. This enables media rich text annotations, but the focus still appears to be on text. It is unclear to me how the data will be represented in the Open Annotation model. Below is an example from Genius.com, demonstrating how a user might embed an image in their annotation:

The Genius.com API documentation reveals that each annotation is essentially an HTML page (https://docs.genius.com/#annotations-h2), whereas Hypothesis is using Markdown to similarly enable media and formatting within text annotations.. This is a simple and effective method of allowing richer annotations than plain text, but is perhaps not quite the same as directly annotating a resource with an image, or video which would, perhaps, be closer to the use cases described in the Open Annotation standard. It also requires that your media resources already be hosted publicly on the web. This would make a closed system, where data and resources are shared selectively, difficult to achieve.
The use of open standards enables ownership of our own data and interoperability with other annotation tools (should we wish to publish a subset or the entirety of our data), but more importantly it allows for a richer set of relationships between annotation resources. These relationships will enable us to satisfy our second requirement, annotation across mediums (maps and text).
Annotating across mediums
While most annotation examples feature a single Target and a single Body, the standard does not prevent us from having more than one of either. It is quite natural to consider a single Target with multiple Bodies. For example, if our Target is the phrase ‘pursuit of Happiness’ appearing in the second paragraph of the Declaration of Independence, there will likely be many interpretations, and therefore annotations of this particular selection.
Similarly, a Body may have multiple Targets. Imagine gathering research on a particular topic. You may want to create a single annotation Body which in turn is associated with multiple resources. For our own application, we are proposing that an annotation created by a user in the field can be associated with both a Target on our map and a Target in our source text. This three part relationship implies a relationship between the two targets which can be used to begin building bridges between the textual world and the material world of our field work.
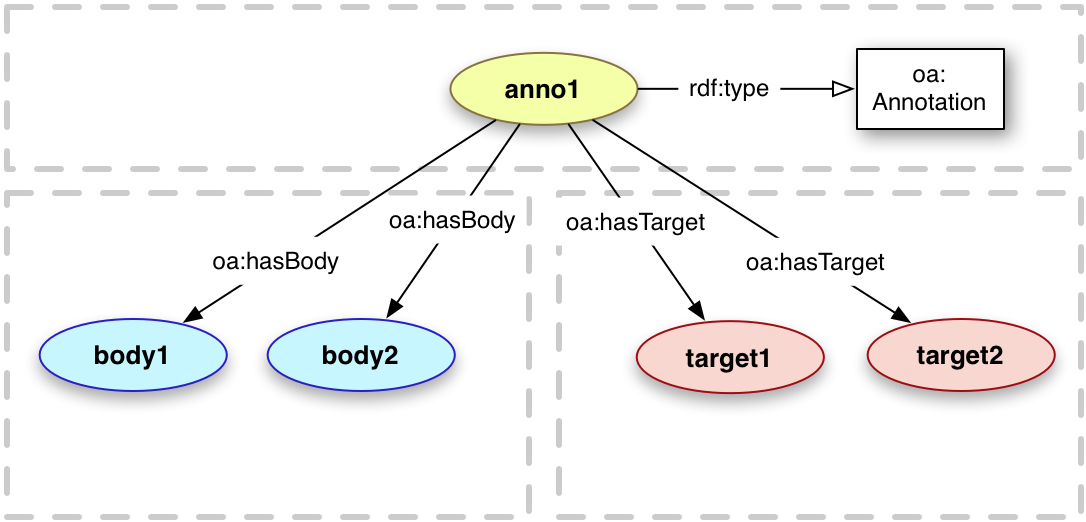
Using an example from the Open Annotation Core specification (above) we can imagine our text as target1 and our map as target2. The associated Body instances are the text and binary annotations created by our users in the field (or at home).
Though we experimented with several open source applications (Maphub, Hypothesis, Annotator.js), all of which make some use of the Open Annotation standard, we have not found anything that meets the criteria described above. Annotating with and across different mediums remains an area that is open for development.
In summary, our requirements for the text component of the larger project are as follows:
- Ability to annotate with different mediums (text, images, video)
- Ability to annotate across mediums (maps and text)
- Ability to serialize this data using the Open Annotation standard, in particular using the model of a single Body with multiple Targets to create implied connections between text and map.
RT @mseangallagher: Annotation, #mLearning, and Geocaching #4: @rexsavior on Annotating Text and Beyond. https://t.co/FlZ7S8jEU5 https://t.…
RT @mseangallagher: Annotation, #mLearning, and Geocaching #4: @rexsavior on Annotating Text and Beyond. https://t.co/FlZ7S8jEU5 https://t.…
[…] Annotation, mLearning, and Geocaching Part #4: Annotating Text and Beyond […]
[…] Annotation, mLearning, and Geocaching Part #4: Annotating Text and Beyond […]
[…] Learning Engineer by ERG Predictions for 2016: Self-Driving Trucks, AI, and Brain Monitoring Annotation, mLearning, and Geocaching #4: Annotating Text and Beyond by Michael […]