 In Part #3 of this series of blog posts on annotation and mLearning, David Fox and I explore map annotation. For easier reference, links to the first few posts from this series are provided below.
In Part #3 of this series of blog posts on annotation and mLearning, David Fox and I explore map annotation. For easier reference, links to the first few posts from this series are provided below.
- Annotation, mLearning, and Geocaching Part #1: Scenarios and Technical Requirements
- Annotation, mLearning, and Geocaching Part #2: The Use Case
In recent years, there have been several efforts by digital humanists to map famous texts. From James Joyce’s Dubliners, to American literature’s famous road trips, to expatriate Paris by way of the Sylvia Beach Lending Library records, there is no shortage of literary maps to explore. Many of these projects make use of popular, web-based, mapping tools such as Google Maps, which serve to present the information in a fashion familiar to most users. Such tools might also enable users to bring these maps into the field where they can experience these literary landmarks firsthand. What these maps do not offer is the ability to annotate or edit the map and then to share these contributions. For example, a student exploring a text in a physical space might want to capture a photograph or a video of a particular location as it exists today.
Thanks to the ubiquity and popularity of mobile map applications many of us have some experience with map annotation. All we need to annotate any map is a set of geographic coordinates comprising a single point, a line, or a polygon. Many of us have done this before. Every pin dropped on a map to identify a favorite restaurant or as a reminder of where the car is parked are, in essence, annotations. In addition, many of the digital photographs we take and share to social media are geotagged, which means that the coordinates associating each image with a particular location are embedded in the photograph’s metadata. Though we may not often browse our image libraries using a map, these too are annotations.
This is all well and good if our literary text is set in the present day; a modern map should suffice for locating and annotating the locations that appear in the text. A more antiquated text might be better associated with a contemporaneous map which may differ in crucial ways from a current map of the same locations. Historic maps must first be geo-referenced to bridge the pixels comprising the image and the geographic coordinates of the locations they represent.
The map of Kyongsong or Seoul (Keijo), Korea (U.S. Army Map Service, 1946) which formed much of the use case for this exercise illustrates the difficulty in geo-referencing historical maps to their current equivalents. The map was created immediately after the end of the Japanese occupation of Korea (1910-1945) and is based on Japanese renamings of Korean place names (Keijo being Seoul, for example) that occurred during the occupation. So the places listed in this map are English transcriptions of Japanese renamings of Korean place names. Further complicating the issue are the events to come a few years after this map was created. The Korean War (1950-1953) decimated the landscape as Seoul was retaken forcibly on separate occasions. In the post-war rebuilding, roads and avenues were widened to allow for car (and military) traffic, yet often maintained their original names. While some landmarks remain, most of the ancient city has been swept away.
{kind=link}
A method for georeferencing is outlined in From Paper Maps to the Web: A DIY Digital Maps Primer. The Primer describes how to use the NYPL’s Map Warper application to upload a historic map, ‘rectify’ the map using a set of control points, and then export a set of geo-referenced map tiles. Once a historic map has been geo-referenced it should be possible for a user to annotate a single location on both the modern and historical map.
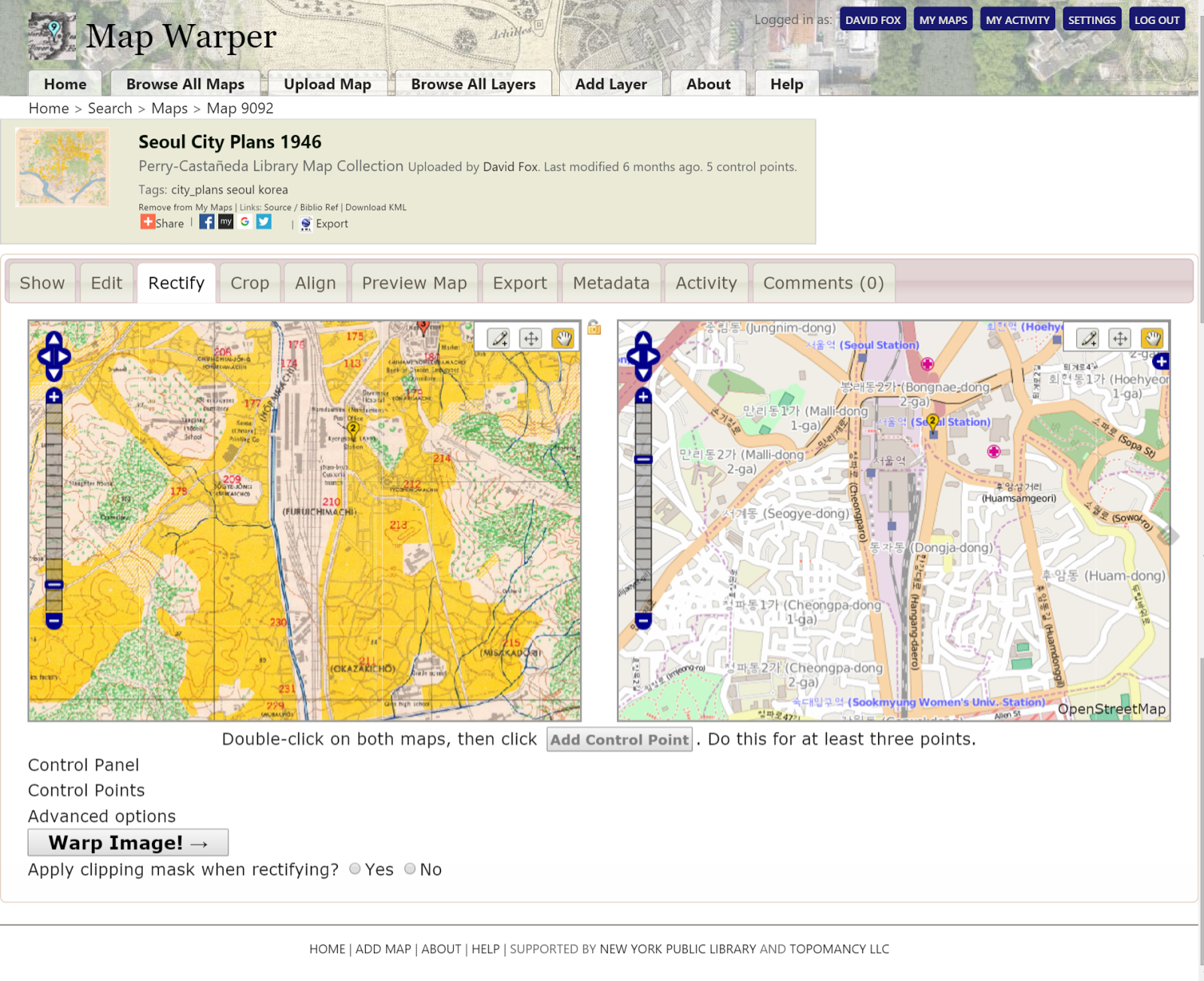
There have been some efforts to enable annotation of historical maps which use some of the principles described above. Maphub, developed at Cornell Information Science, is a web application for viewing and creating annotations of historic maps. The application supports both georeferencing and annotation of identified locations. Maphub makes use of the Open Annotation standard (more on this below) and the application itself is open source, making it a good candidate for our project.

Every annotation requires a Target—defined by the Open Annotation model as a part of the full resource (in this case, a location on a map)rather than its full extent (the map entire). Maphub identifies Targets with an SvgSelector that uses the Scalable Vector Graphics standard to define an area of interest using coordinates of the image itself in pixels. It also provides a secondary selector, custom to Maphub, which expresses the same information in The Well-known text (WKT) markup language. Both selectors allow us to draw our location on the map image, but only the latter is intended to encode geographic coordinates.

Despite its use of the WKT standard, the Maphub application fails to encode actual geographic coordinates. If we look at sample data produced by Maphub we can see that the coordinates are the same in each Selector:
<2752261a-d14b-11e1-b9b2-00163e110825> a ct:ContentAsText;
dcterms:format “image/svg”;
ct:chars “””
<?xml version=”1.0″ standalone=”no”?>
<polygon xmlns=”http://www.w3.org/2000/svg”
points=”5315,5639 5444,5529 5505,5593 5346,5691 5315,5639″ />
“”” .
<27527570-d14b-11e1-b9b2-00163e110825> a ct:ContentAsText;
dcterms:format “application/wkt”;
ct:chars “POLYGON((5315 5639,5444 5529,5505 5593,5346 5691,5315 5639))” .
The data above describe a selection of the map image and cannot be used to identify a place on a map. Without these geographic coordinates it is not possible to enable geographic search—which enables the user to find annotations ‘near you’—or geotagging of user created annotations.
Though it is not a requirement that the application we create or select for this use case support the Open Annotation standard, it would certainly be a benefit to other students of a text to be able to share the results of any field work around a particular text. For example, students at Trinity College Dublin are uniquely positioned to annotate Dubliners and then to share that work with students elsewhere in the world. Certainly, there are many ways one might express an annotation that would serve our core needs, but the Open Annotation model–a W3C standard that is already in use by several applications–will aid collaboration across institutions.
What other tools might be used to fill these gaps? If the historical map is considered to be mostly informational then there is little need to tie our annotations to both geographic coordinates and to a selection of the map image. The georeferenced map can be exported from a tool like Map Warper and imported as a layer into any map application, such as Google Earth (seen above). This layer could be used for reference and discarded at a later point in the project.
We need to bring the pre-coordinated annotations, which link our text to a physical space, with us into the field. We also need to create our own annotations as we visit these locations. We may then wish to amend a location which has proven to be incorrect, or to add a location that was not previously associated with the text. As seen above, some of the component pieces that would enable the described activity exist already, sometimes in an imperfect form, but there is as of yet no one solution that meets our requirements. The applications discussed above for enriching and annotating historic maps are not sufficient for the work we hope to do in the field. And though most of the media we capture on our mobile devices is already geotagged, there is some work required to extract the location information and create links to the pre-coordinated positions identified from our source text.
In summary, our requirements are the following:
- Ability to georeference a historical map producing a reference layer in our preferred map application and enable a bridge between location names mentioned in the text and modern names of these locations
- Ability to annotate a particular location on a map, defined by a set of geographic coordinates
- Ability to navigate these annotations in the real world, ideally using a mobile application
- Ability to contribute annotations to the map (e.g. photos, video, or text)
- Ability to amend or add to annotations on the map
- Optionally, serialize our resulting data using the Open Annotation standard
In Part #4, we will discuss annotating text before attempting to bring all these disparate bits together.
Annotation, mLearning, and Geocaching Part #3: Annotating Maps https://t.co/GAHlhbHqql
Annotation, #mLearning, and Geocaching Part #3: Annotating Maps with @rexsavior https://t.co/XJkw2OZelF #Seoul https://t.co/2tHn0ReGvt
Annotation, mLearning, and Geocaching Part #3: Annotating Maps https://t.co/8wbF8nVD4n #gis #map
Annotation, #mLearning, and Geocaching Part #3: Annotating Maps. https://t.co/108e37V2s6 https://t.co/RtRlmEI2pv
RT @mseangallagher: Annotation, #mLearning, and Geocaching Part #3: Annotating Maps. https://t.co/108e37V2s6 https://t.co/RtRlmEI2pv
[…] Annotation, mLearning, and Geocaching Part #3: Annotating Maps […]
[…] Annotation, mLearning, and Geocaching Part #3: Annotating Maps […]
[…] Annotation, mLearning, and Geocaching Part #3: Annotating Maps […]